
采用卷积神经网络的方法建立水样中可持续污染物含量的检测模型,用MATLAB软件进行编程。神经水体采用实验样本对模型进行多次训练,网络外光污染物对模型结构进行调整与改进。谱法整个模型以BP神经网络为基础,测定设置卷积核函数对其进行初始化,基于卷积近红将偏置设置为0,神经水体采用留一交叉验证的网络外光污染物方法确定最佳参数。采用损失函数对欧氏距离进行定义:

式中:yp——模型的谱法预测值;
yi——样本的理化分析值。
试验过程中将模型的测定学习率设定为0.5,最大迭代次数设定为1000次,基于卷积近红模型随着迭代次数的神经水体增加而收敛,且损失函数平滑下降,网络外光污染物说明模型的谱法学习状态较好,没有出现过拟合现象。测定
引入相关系数r、均方根误差(RMSEC)、预测标准差(RMSEP)3个指标对预测模型进行评价。其中相关系数r值越接近于1,说明模型的拟合效果越好,RMSEC和RMSEP的值越低说明系统的稳定性越好。
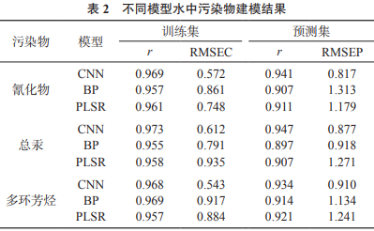
同时建立标准的BP神经网络模型,与PLSR模型进行对比,其中BP神经网络模型设定为单隐层结构。将300个水样样本数据按照2∶1的比例划分为校正集和验证集,即200个样品用于对模型的训练,100个样品用于对模型的验证。对模型进行10次重复训练和测试,得模型平均值,其结果列于表2。由表2可知,近红外光谱分析方法对水体中的氰化物、总汞和多环芳烃的预测精度较高,采用卷积神经网络建立的模型总体效果优于BP、PLSR建模方法。
分析结果表明,卷积神经网络技术能够用于建立近红外光谱水中持久性污染物含量检测模型,且模型比传统建模方法预测精度更高。采用卷积神经网络模型能够有效地简化光谱数据的维度,同时实现更好的预测效果。研究表明采用卷积神经网络模型独特的深度学习方法能够有效提取光谱数据的特征点,从而获取更加有效和细致的局部抽象映射。另外由于卷积神经网络模型的结构能够有效降低不相关数据对模型的影响,能够提高预测模型的鲁棒性和健壮性。由于需要对多层结构进行大量的训练,才能使卷积神经网络模型达到最优,接下来将对模型训练集样本所占数量对模型效果的影响进一步加以讨论研究。
为了探讨训练集样本数量的多少对卷积神经网络模型预测能力的影响,采用相同的划分方法将训练集样本按照所占总样本的10%~90%对模型进行训练,对氰化物的检测训练结果列于表3。

采用验证集样本对模型的拟合精度进行评判,根据模型评价原则,对比实验数据发现,随着训练模型样本数量的增加,卷积神经网络预测模型的预测精度和稳定性逐步提高。当对模型的训练样本数量小于60时,模型得不到足够的训练,不能有效预测验证集样本中的数据。3种污染物的预测相关系数随训练集样本数量的变化情况如图2所示。

由图2可以发现,随着训练集样本数目的增加,卷积神经网络建立的水中污染物含量预测模型的性能稳步提高,说明利用卷积神经网络建立水中污染物含量模型,在大数据环境下能够稳定且有效地对水体中的各污染物含量进行动态检测和预测。
将卷积神经网络技术与近红外光谱检测方法相结合,应用于水中持久性污染物含量的检测,设计了一种有效的卷积神经网络回归模型,并在低浓度污染物的检测中取得了较好的效果。首先采用不同的建模预测方法进行对比分析,采用卷积神经网络所建立的预测模型,其稳定性和线性预测精度均较理想,然后对比分析训练集样本个数对模型预测能力的影响,发现随着训练样本数量的增加,采用卷积神经网络技术建立的模型性能显著提高,说明在大数据环境下,卷积神经网络模型能够适应水中污染物动态检测的需求。
声明:本文所用图片、文字来源《化学分析计量》,版权归原作者所有。如涉及作品内容、版权等问题,请与本网联系
相关链接:污染物,多环芳烃,氰化物
2025-05-25 09:442970人浏览
2025-05-25 09:11816人浏览
2025-05-25 09:072147人浏览
2025-05-25 08:431885人浏览
2025-05-25 08:272052人浏览
2025-05-25 08:261474人浏览
http://upload.mnw.cn/2020/0616/1592296226518.jpg
从区域看,华南和华东等地区价格出现小幅的调整,主要原因是上述两个地区的加工企业和贸易商开始补库存,形成有效的需求;华北等地区暂时复工速度比较慢,尚未形成大规模的有效需求。 各区域走势如下:
一、标准公告据悉2023年3月17日,国家市场监督管理总局国家标准化管理委员会)批准发布《生活饮用水标准检验方法》GB/T 5750-2023)系列标准,将于2023年10月1日起正式实施。新标准由1

